最近搜索
暂无搜索记录
热搜

JAVA
大数据
分布式
Python
人工智能
爬虫
WEB
JavaScript
认证

 0
0 登录
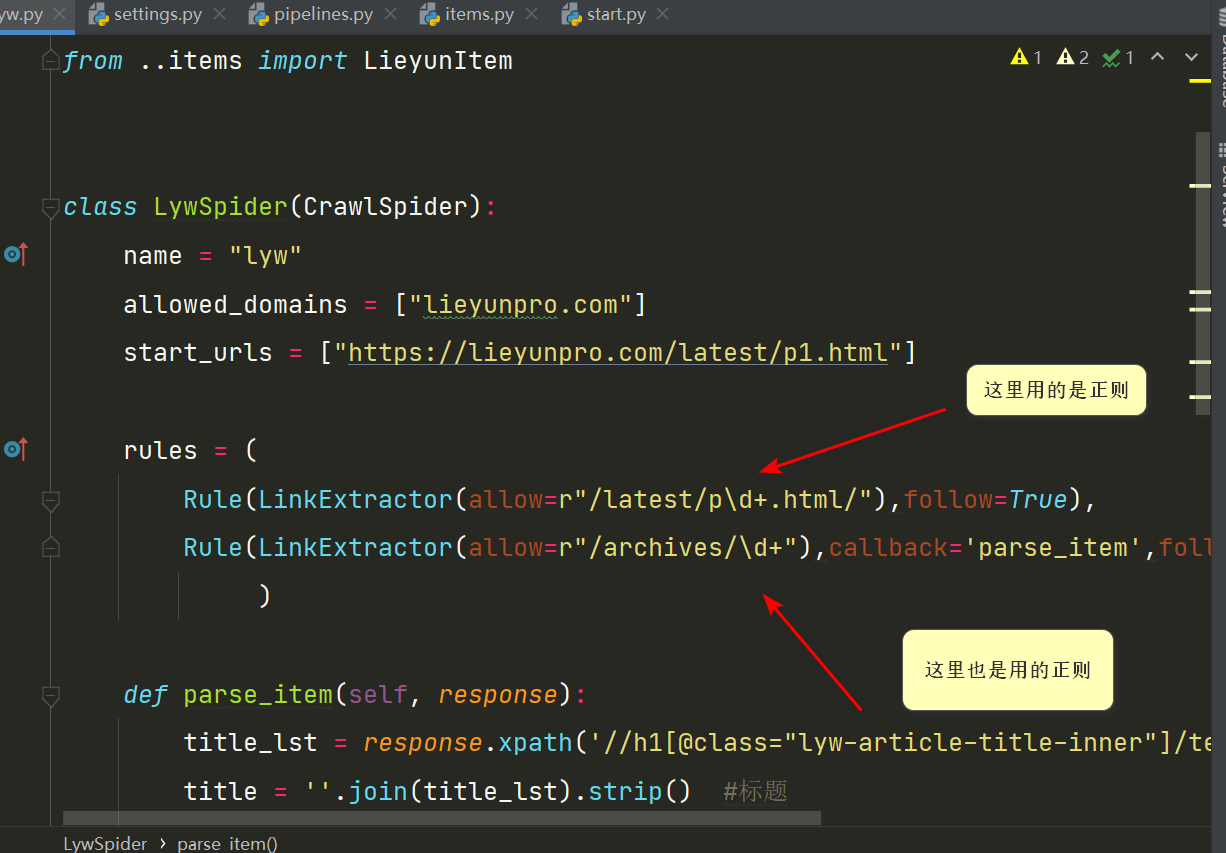
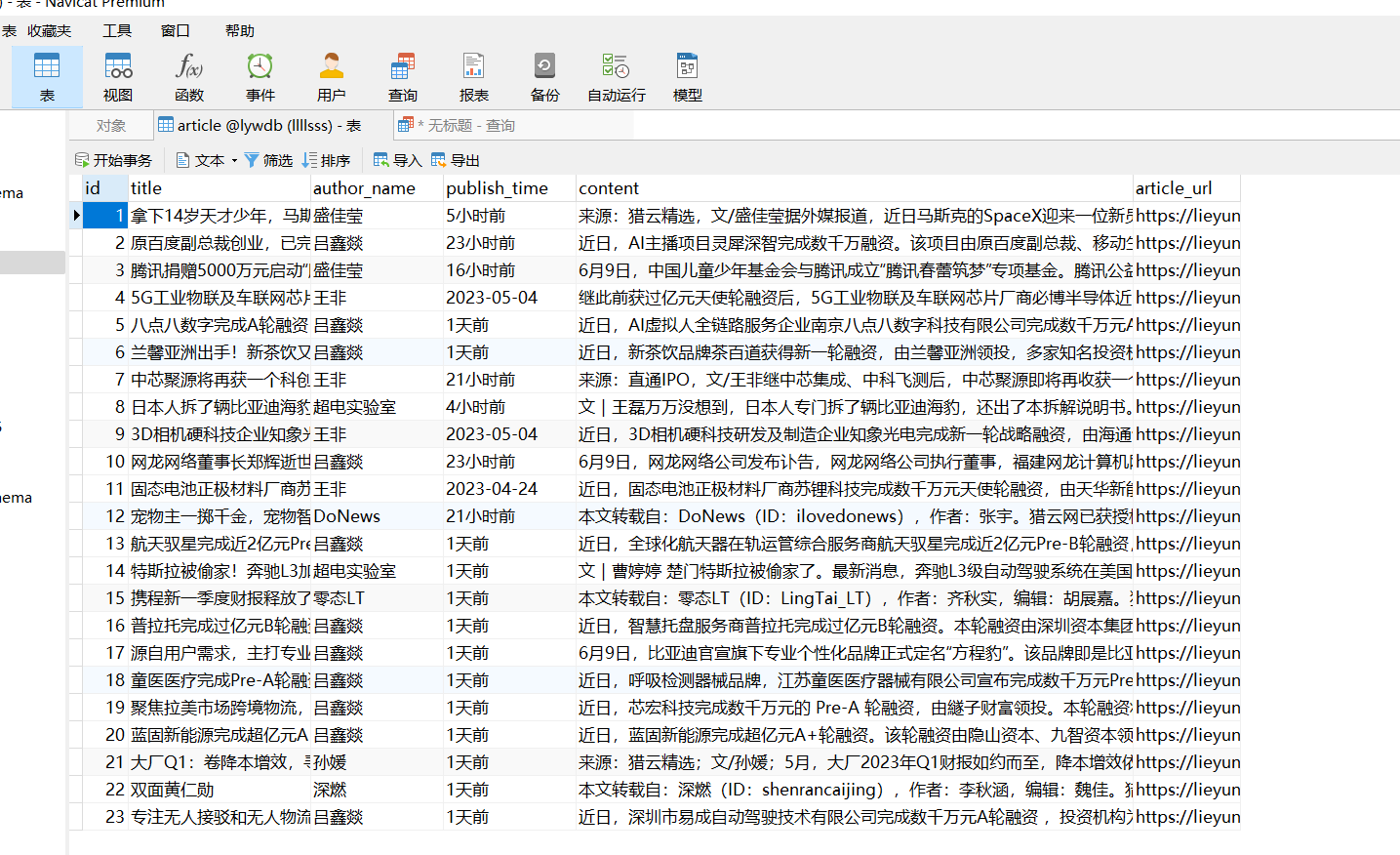
登录老师,爬取数据的数量不对?同样是用了正则,杨老师在讲课的视频中就能爬取100多数据,而我的只爬取了2个数据,应该是一页中的内容,难道正则写错了吗?
# coding:utf-8
from scrapy import cmdline
cmdline.execute('scrapy crawl lyw'.split(' '))
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import LieyunItem
class LywSpider(CrawlSpider):
name = "lyw"
allowed_domains = ["lieyunpro.com"]
start_urls = ["https://lieyunpro.com/latest/p1.html"]
rules = (
Rule(LinkExtractor(allow=r"/latest/p\d+.html/"),follow=True),
Rule(LinkExtractor(allow=r"/archives/\d+"),callback='parse_item',follow=False),
)
def parse_item(self, response):
title_lst = response.xpath('//h1[@class="lyw-article-title-inner"]/text()').getall()
title = ''.join(title_lst).strip() #标题
publish_time = response.xpath('//h1[@class="lyw-article-title-inner"]/span/text()').get() # 发布时间
author_name = response.xpath('//a[contains(@class,"author-name")]/text()').get() # 作者
content = response.xpath('//div[@class="main-text"]//text()').getall()
content = ''.join(content).strip()
article_url = response.url
# 创建Item的对象
item = LieyunItem()
item['title'] = title
item['author_name'] = author_name
item['publish_time'] = publish_time
item['content'] = content
item['article_url'] = article_url
yield item
# print(title)
 1
1 写回答
写回答




 微信小程序
微信小程序 微信公众号
微信公众号 下载APP
下载APP 品牌/商务合作:4000015096
品牌/商务合作:4000015096



